
Cookie Settings
We use cookies to operate this website, improve usability, personalize your experience and improve our marketing. Your privacy is important to us. Privacy Policy.
December 03, 202510 min read
From context to simulation: How class 3 and class 4 data make predictive AI possible
Share
In many industrial systems, the sensors are loud, but the data is vague.
AI can replicate existing control strategies—and in many cases, perform them reliably. But to go beyond matching a manual baseline and actually improve outcomes, the system needs more than surface-level data. It needs to understand why things happen. That’s where AI data classification comes in. At Phaidra, we use this framework to structure data so that AI agents go beyond pattern recognition and into meaningful, predictive control.
Class 2 data shows behavior. Class 3 explains it. Class 4 prepares for what hasn’t happened yet.
If you need a refresher on Class 0, 1 and 2 data, check out our explainer here
We’ll focus on the high end of the classification spectrum that enables both foresight and hindsight.
Here’s what you’ll take away from this breakdown:
How Class 3 and Class 4 data differ in purpose and potential
Why simulated data isn’t hypothetical — it’s essential to system safety
How Phaidra uses these data classes to train agentic AI in real-world environments
Let’s start by exploring why this classification system matters — and what’s at stake when AI is fed the wrong kind of data.
Why AI Data Classification Matters, Especially for Control Systems
Not all data is created equal, especially when you're asking AI to make decisions with it.
AI data classification is a framework for assessing how useful a dataset is for intelligent automation. At the lowest levels, you’re dealing with unstructured or raw data (Class 0), then structured and semantically labeled data (Class 1), and finally cleaned, validated signals with timestamps and context (Class 2). But Class 2 is still just surface-level: the AI sees what happened, but it doesn’t understand why—and that’s a problem when it’s tasked with controlling real-world systems.
It’s the difference between spelling words correctly and understanding the meaning of the sentence.
Without contextually rich data, AI is left guessing—extrapolating from shallow patterns, unable to see the causal relationships that matter most. In systems like industrial cooling or power management, that kind of guesswork isn’t just inefficient… it’s risky. That’s why Phaidra’s AI doesn’t operate on what’s convenient. It operates on what’s complete, enriched, and ready to support autonomous control decisions.
So what exactly makes data “ready” and what sets Class 3 and Class 4 apart?
Class 3 Data — Contextualized and Dynamically Rich
Clean data is nice, but context is what makes it extremely valuable to the organizations utilizing it for decision-making.
Class 3 data is what happens when you stop just recording a system and start understanding it. It goes beyond complete and clean; it’s enriched with variation, context, and external signals that help AI grasp how a system actually behaves under different conditions. This includes things like operational variability — changes in setpoints and the corresponding sensor feedback that together reveal how the system behaves across its full range. It also includes integrating external data, like weather conditions that affect system load and/or performance.
Without this kind of data, the AI is flying blind through anything it hasn’t seen before—and it can’t learn better strategies if it’s only trained on tightly constrained system behavior. That’s why Class 3 data is foundational for smart control.
It gives AI the ability to map cause and effect, learn from corner cases, and prepare for real-world complexity, which is more important than textbook scenarios.
“
Class 3 data is how AI sees beyond the peephole
”
Akshay Jindal, Sr Data Scientist at Phaidra
Here’s what Class 3 data enables:
Modeling of edge cases the system hasn’t encountered in daily operation
Backfilling of missing data by learning system dynamics
Feature generation for training simulators and agents
Imagine a data center that’s only ever run at 40% load. That data might be clean, but it’s not very helpful if your AI needs to control for a 65% load spike. Class 3 data enables AI to operate within those ranges safely, intentionally, and with purpose.
So what happens when AI doesn’t just understand how systems behave but can also accurately predict what comes next?
Class 4 Data — Predictive, Generative, and Forward-Looking
Understanding a system is great, but predicting it is next-level.
Class 4 data represents a leap in capability:_ it’s generated by simulators or digital twins that are trained on enriched Class 3 data_. Unlike earlier classes, which come from sensors and historical logs, Class 4 is synthetic; it’s forward-looking data created to simulate how a system might behave under new or extreme conditions. It allows AI to anticipate, besides simply responding.
Where Class 3 is observational, Class 4 is generative.
This is data that can think beyond what it has seen.
It’s the foundation of predictive control. It allows AI to rehearse scenarios before they occur, test actions before they’re taken, and develop strategies for edge cases that haven’t happened yet (and ideally never will). Crucially, these simulations are grounded in physics and real system dynamics.
We’re not inventing fantasy data.
Instead, we’re extending reality with constraint-based foresight.
Examples of what Class 4 data enables:
Forecasting future cooling loads based on external weather predictions
Simulating power outages or equipment failures to train AI agents on recovery paths
Modeling valve behavior under stress to prepare for rapid load changes
Because Class 4 data is generated from accurate Class 3 dynamics, every scenario stays within the bounds of what’s physically possible. It’s not just “what if” data; it’s “what now” intelligence, built from a system’s own rules.
So how does this future-facing data translate into real-world action, especially when paired with AI agents tasked with making decisions?
From Insights to Agentic AI
Seeing a problem is good. Solving it before it happens is better.
At Phaidra, Class 3 and Class 4 data do more than sit in a pipeline. They fuel two distinct but connected capabilities: insights and autonomous agentic control. On the insights side, Class 3 data adds the system context needed to detect anomalies and understand faults in real time. With Class 4, you move from awareness to foresight — simulating failure states that haven’t occurred yet to train models to recognize them when early signals emerge.
Reacting fast is good, but reacting fast with incredible accuracy is better.
That’s why prediction needs purpose.
This is especially useful in high-stakes environments like data center operations, where AI agents must make decisions about thermal management, energy use, and system stability in milliseconds — not minutes. In our work with Cooling Distribution Units (CDUs), for example, agentic AI trained on Class 4 data doesn’t wait for the thermal system to overshoot the supply water temperature. It acts before the spike hits — because it’s been trained on Class 4 data to recognize the early signs, like rising IT load.
It looks like magic, but it’s actually preparation.
How Class 3 and 4 data power Phaidra’s agents:
Insights: Analytics & Observability
Class 3 enables richer fault detection and causal understanding
Class 4 makes predictive maintenance possible by simulating future failure states
Comparing simulated (expected) vs. real (actual) values helps flag early anomalies
Agentic AI for CDUs
Proactive control based on forecasted IT load spikes

Phaidra’s self-learning AI agent is substantially better at reducing thermal spikes than traditional control systems.
Valve and flow behavior simulations train agents on how to respond preemptively
Preventing unsavory futures before they unfold
With simulation data, agents don’t start from zero. They start informed. That means they can reach human-caliber performance quickly, then learn alongside real-world operators. As they improve, operators get time back to focus on higher-value work instead of manual tuning.
So what makes this possible behind the scenes? It’s not just smart code. It’s the coordination and complexity required to generate the right kind of data in the first place.
Challenges in Moving from Class 2 to Class 4
Turning raw data into predictive intelligence is more organizational than it is technical.
New to data classes? Read our breakdown of Class 0–2 here.
Getting to Class 4 data isn’t a matter of adding more sensors or writing more code. It takes purposeful exploration, cross-functional coordination, and the discipline to build systems that reflect how the real world actually works. At Phaidra, moving from Class 2 to Class 4 means going beyond clean data pipelines into rich semantic context, meaningful variation, and physics-grounded simulation, all while making sure the AI is solving the right problem.
In other words, this isn’t plug-and-play.
It’s test, train, verify, align.
Here are the biggest challenges, and how we tackle them:
Problem: Class 2 data doesn’t explore system dynamics
It may be clean, but it’s often shallow—reflecting tightly constrained operations with limited variation. Without controlled experimentation, you don’t get the behavioral range needed for Class 3 enrichment.
Solution:
We work with partners to conduct targeted operational variation—manually adjusting setpoints and operating modes to help AI learn how the system behaves across its full range. That exploration becomes the foundation for modeling and simulation.
Problem: Organizational silos slow down data enrichment
Engineering teams understand the system. Data science teams build the models. Product teams know the use cases. But without coordination, context gets lost — and models miss the mark.
Solution:
We bring these groups together early. Domain experts inform the ontology. Data scientists create the mappings. ML engineers and research teams train and refine the models. The product ensures the right goals are baked into the training. This isn’t a handoff — it’s a collaboration loop.
Because we’ve worked in controls, data centers, and AI, we don’t need to guess how these systems operate. We use that background to move faster and design solutions that fit the real-world constraints from day one. Phaidra’s team brings deep expertise in artificial intelligence applied to mission-critical cooling infrastructure.
Problem: Data alone doesn’t create intelligence
Raw telemetry is just numbers. So it doesn’t carry much meaning on its own. In most building systems, data points are labeled inconsistently—if they're labeled at all. One chiller might show up as chiller1 while another shows as ch101, but neither tells the operator much without a decoder.
The risk isn’t that AI gets it wrong—it’s that it doesn’t know what right looks like.
Here’s what that transformation looks like, taking raw tags to semantically enriched Class 3 data that an AI agent can understand and act on:
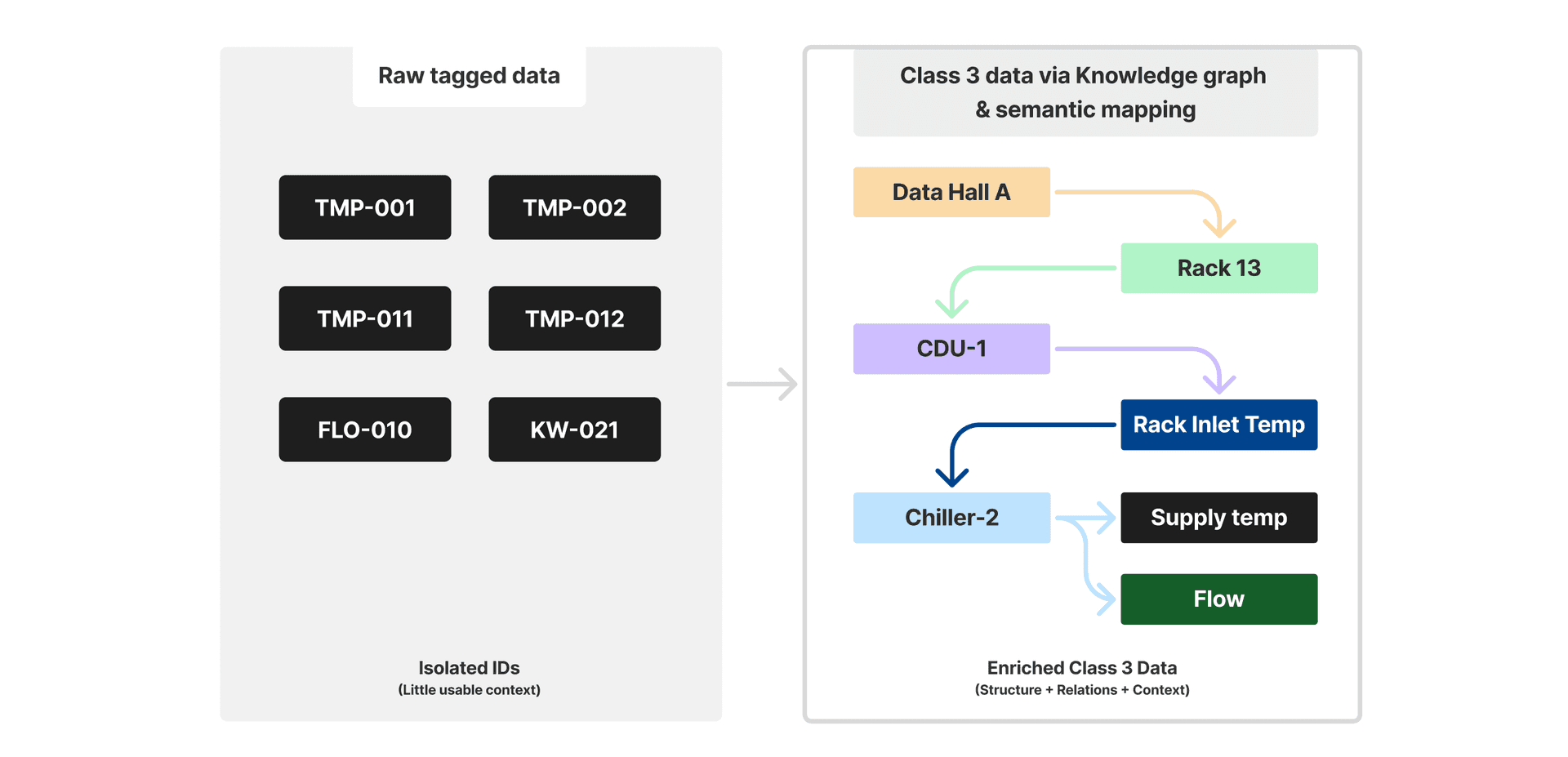
Raw industrial data tags vs Class 3 enriched data
Solution:
We semantically map raw data, then build knowledge graphs to define how components interact. This gives the AI more stable, informative, and context-rich inputs — showing what affects what and why. We embed those relationships into simulators, enforcing the physics and rules of real-world operations. That’s how we make sure Class 4 data isn’t just synthetic — it’s believable, usable, and safe.
Scaling from Class 2 to Class 4 isn’t just about readiness. It’s about responsibility — making sure the data, the tools, and the teams are aligned to support AI that can act with confidence.
From Clean to Capable
AI needs more than clean data.
It needs the kind of data that tells a story, reveals patterns, and prepares it for what’s ahead. That’s what Class 3 and Class 4 data make possible.
Here’s what we covered:
Class 3 data provides the context and variability needed to model system behavior
Class 4 data is the result of simulation and enables foresight and predictive decision-making
Phaidra’s AI services use both to safely navigate complex environments with confidence
But enabling this takes exploration, coordination, and a commitment to grounding every insight in reality. The payoff is AI that doesn't blindly guess. It understands, anticipates, and adapts.
This is just the beginning.
As industrial systems generate richer data and AI agents become more capable, the gap between reactive and predictive control will only widen.
So the question isn’t: Do we invest in support for generating and maintaining Class 3 and 4 data?
It’s “How quickly can we get there?”
Featured Expert
Learn more about one of our subject matter experts interviewed for this post

Akshay Jindal
Senior Data Scientist
As a Senior Data Scientist, Akshay is responsible for building tools and processes for dealing with complex sensor data for mission critical systems the help AI agents deliver high value decisions. He collaborates with engineering teams to develop solutions for fall detection and diagnosis, data analysis and troubleshooting. With background in controls and data science, Akshay has years of experience in designing and implementing HVAC controls systems, with expertise in data modeling, performance benchmarking, and machine learning.
Tags:
AI
Share
Recent Posts

AI | March 16, 2026
Phaidra, in collaboration with industry leaders NVIDIA and CoreWeave, announced a groundbreaking methodology to drastically improve the thermal stability of liquid-cooled AI data centers.

Product | March 04, 2026
Phaidra Prism is an AI assistant designed by data center experts for data center operators and technicians.

AI | January 07, 2026
An AI factory operates more like a formula 1 race car, not a typical data center. Find out how Phaidra's AI agents deliver real-time thermal control for synchronized GPU workloads at gigawatt scale while working with a broader partner ecosystem.
Subscribe to our blog
Stay connected with our insightful systems control and AI content.
You can unsubscribe at any time. For more details, review our Privacy Policy page.
